Enhancing Horse Racing Outcome Prediction through Feature Selection and Machine Learning Techniques
Authors :
Dr. B.Lavanya
Address :
Teaching Assistant, Department of Computer Science, Periyar University, Salem
Abstract :
Horse racing is a fascinating sport for people of all abilities due to the intricate relationship between rider expertise, previous results, family history, and track conditions. Satisfying yet challenging endeavor for gamblers, instructors and experts alike is horse competition forecasting. In the last decade, an attractive choice that become to estimate the horse results are Artificial Intelligence (AI) approaches using enormous amounts of complex algorithms and data. Choosing and refinement of pertinent variables in order to achieve reliable forecasting are addressed in this study. This research explores the efficacy of various Feature Selection strategies for Support Vector Machine Models in Horse Racing (FSSVM-HR) outcome prediction. The technical challenges associated with irregular interactions, heterogeneous factors and managing massive databases are addressed with a focus on correct theory implementation using this implemented Machine Learning (ML) technique. Most important variables in forecasting competition results are determined through the number of factors including past race efficiency, circuit factors, animal speed and rider ability looks at a algorithm. The outcomes of the algorithm provide deeper understanding into the variables affecting the outcomes of horse race events and show that it has the ability to execute better than conventional approaches. This research adds to the literature on statistical analysis in horse betting, competitive organization choice, and provides useful information for smart betting.
Keywords :
Artificial Intelligence, Machine Learning, Computational Challenges, Feature Selection, Horse Racing Prediction, Betting.
1.Introduction
Due of the high rewards and severe competition, jockeying is always famous among audience, gamblers, and professionals [1]. Predicting an animal's success in a competition is challenging for many reasons, including the animal's past racing results, the rider's skill, the animal's current form and the track circumstances, [2]. Despite these obstacles, data-driven approaches have transformed the industry, making accurate predictions more difficult but not impossible [3]. Positions, previous results of horses, events schedules, and other variables are all part of the jockeying outcomes data set [4]. Jockeys' handling tactics and successes are crucial since they greatly affect the outcomes of competitions [5]. Competition performance is also greatly affected by environmental factors, such as circuit circumstances - circuit type, weather, and appearance).
The data from horse racing analytics, you can see patterns and cycles that can help you predict what the future holds [6]. Common components of these analyses include data on the cattle's individual strengths and weaknesses, average winning percentages, and the impact of course conditions on race outcomes [7]. This data can help gamblers, teachers, and other players make more informed decisions [8]. Without the need for explicit code we can learn from knowledge and advance in the software produced by Computational intelligence's neural networks division [9]. In the racing industry, to examine massive amounts of spot trends and data that may have undetected Artificial intelligence is beingused [10]. Since it provides an empirical foundation for tactical choices and forecasts the approach is revolutionary for athletics [11]. An essential component, which is used to track jockey results in artificial intelligence, is choosing features. To do this, one must first identify which collection attributes are most relevant and hence most predictive [12]. This method improves the model's precision while decreasing the amount of calculations and the number of possible over fitting scenarios. Racetrack conditions, horse speed, rider expertise, and past performance data are commonly used to predict gambling outcomes [13]. An increasing in number of approaches for predicting and evaluating race outcomes have made the utilization of artificial intelligence in the racing industry in recent years. The correlation between a dependent and independent variable can be represented statistically using regression. Trees of choices are often utilized in classification tasks to filter data according to numerous criteria and discover the most likely conclusion [14].
While Artificial Neural Networks (ANN) are designed to mimic the structure of the human brain and excel at recognizing complex patterns and predicting relationships between different variables, ensemble techniques like Random Forests and gradient boosters take it a step further by combining insights from multiple models to improve their overall accuracy. Researchers and personal trainers can utilize these advanced technologies to develop predictive algorithms that provide deeper insights into jockeying performances [15]. Those structures can be utilized to enhance decision-making, event management, and strategic betting, all of which enhance the overall experience for both participants and spectators [16]. Overall, the field of jockeying presents a challenging yet highly profitable opportunity for prediction, driven by the interplay of numerous factors [17]. Through the use of technology training and strategic selection of relevant features, experts can create forecasting algorithms that offer precise and valuable insights into racial issues [18]. With the right mix of data, analysis, and forward-thinking, the racing industry for horses has the opportunity to undergo a remarkable transformation. By providing individuals with a solid scientific foundation and increasing public awareness, this traditional activity can reach new heights [19]. As artificial intelligence advances, more chances will present themselves in the sport, making it more enjoyable for all participants.
Main Contributions
- To enhance the prediction outcome of racing events by applying Feature Selection strategies for Support Vector Machine Models in Horse Racing (FSSVM-HR) for better precision.
- To improve coaching judgments, wise gambling and event leadership the research develops models that take into account rider expertise, racecourse situations, and horse abilities.
- The findings of this study improve understanding of racial forecasting and give useful information to company executives.
The outline and scope of this research are presented in Section II. The proposed ML approaches employed in this study are presented in Section III. Section IV includes the dataset description followed by performance results and discussion are presented in Section V. Conclusions and further research are summarized in Section VI..
2. Literature Survey
Methods for predicting the outcomes of machine-assisted horse training: A Survey by Smith et al. provided a comprehensive overview of several AI approaches, including as ensemble techniques, neural networks, and choice trees, and how they are applied to jockey forecasting. Choosing more beneficial traits can boost predictions for the economy and precision in horse racing, according to the investigation, which highlights the importance of decision-making in efficiency prediction [20]. The use of data mining and machine learning techniques for horse racing predictions is a magazine article written by Lee and Kim provided a thorough analysis of Data Mining (DM) and Neural Network (NN) approaches as they pertain to jockey predictions. In its examination of these paths, the study assesses the impact of multiple points of data on the accuracy of predictions, such as racetrack conditions, rider histories, and equine recorded histories. The article elucidates the role of different types of data and how they impact the performance of algorithmic predictions in the racing business [21].
Patel and Singh's provided an analysis of various feature selection methods applied to the context of jockey success prediction. The review emphasizes the need of selecting suitable characteristics for efficient model prediction, such as riding knowledge, horse pace, and circuit circumstances. Focusing on these crucial components can enhance model precision and total forecast results for racing horse predictions, according to the study [22]. Research by Johnson et al. explored the utilization of combination approaches, such as Random Forest (RF) modeling and Gradient Boosters (GB), for the purpose of racing forecasting. In order to provide more precision in forecasts, the methods combine many models [23]. By pooling the strengths of several models, collaborative approaches to event prediction increase both dependability and accuracy. Garcia and Martinez's investigated the application of neural networks and deep learning techniques to the prediction of jockey performances. Several designs are evaluated in this analysis based on how well they reflect and maintain the relationships found in the data. Advanced algorithms can understand intricate patterns and correlations in data pertaining to racehorses, which could lead to reliable forecasts [24].
An analysis of machine learning algorithms for predicting horse bets by Zhao et al. compares the effectiveness of various ML algorithms in predicting the outcomes of jockey races. These algorithms include Logistic Modeling (LM), Support Vector Machine (SVM) learning, and k nearest neighbors (KNN). Finding the most effective approaches in different contexts, the study weighs the pros and cons of each approach [25]. Finding the most effective methods for making accurate and dependable horse racing predictions is what this investigation is all about. The study conducted by Wang and Chen explored the fascinating realm of jockey result forecasts using Artificial Intelligence. The paper delves into the possibilities and challenges of collecting, organizing, and creating data, highlighting the crucial role these processes play in precise forecasting and reliable forecasts [26]. Resolving these variables could potentially lead to improved prediction and decision-making when it comes to betting on horses.
3. Research Methodology
The initial stage of utilizing AI strategies and selecting features for predicting racing outcomes involves data setup and collection. In order to achieve the primary objective of this research, which is to construct an accurate predictive model for the outcomes of horse racing, with the intention of improving prediction performance through the utilization of ML techniques and methods for selecting features. Gather information from various sources, such as productivity information, event results, and past horse riding data. As depicted in Fig. 1, the general working procedure of the FSSVM-HR is depicted below.
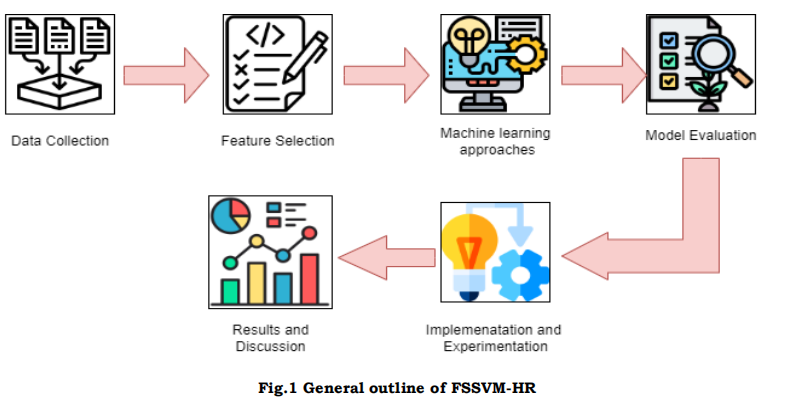
Data Preparation:
. Important factors for predicting the results of horse races are included in the dataset, such as rider expertise, previous performances, family history of the horse, and track conditions. Analyze the details regarding the horses, jockeys, trainers, and the race itself from the dataset. The observed data is more understandable by filling in missing numbers, correcting inconsistencies, and removing superfluous information through preprocessing. Incorporating other components such as the capacity to ascertain past performance patterns for riders and cattle, a racecourse environment that is suitable for separation and the periodicity of race outcomes can enhance the approach's effectiveness. Create data sets for use in development, verification, and evaluation.
Feature Selection: Prior to making a feature selection, it is necessary to identify the potential race-influencing factors, such as horse characteristics, rider and handler expertise, competition type, distance, and circuit conditions. Sort characteristics by how important they are for predicting racial outcomes using computer tools like regression analysis and reciprocal data. Reduce the complexity of the data space using dimensionality reduction approaches like Principal Component Analysis (PCA) to avoid over fitting. Horse racing predictions are made using relevant features. This process comprises choosing prior performance ratings, track circumstances, jockey skills, and other considerations. Loop standardization or RFE are two methods that can help you choose important attributes. Decision trees, logistic regression, random forests, support vector machines (SVMs), and neural networks are some of the artificial intelligence calculations that are selected throughout the model-development process. To educate each chosen model, use the learning data, and to tweak variables, use the validation data. Find the sweet spot for the model's upper-level parameters using techniques like grid search, random hunting, or Bayesian optimizing. The Recursive Feature Elimination (RFE) technique is applied for feature selection based on their importance score and represented using Eq. (1).
𝑅𝐹𝐸𝑆𝑉𝑀 = 𝑎𝑟𝑔𝑚𝑖𝑛𝑥 ′𝐶𝑉(𝑥 ′ ) (1) The variable 𝑅𝐹𝐸𝑆𝑉𝑀 represents the feature subset like jockey, age, condition, level of race track to evaluate the prediction of race outcome using this FSSVM-HR model. The 𝐶𝑉 defines the cross-validation performance of the SVM model with feature subset 𝑥 ′ . This equation set provides a methodical way to pick important features for enhancing the performance of ML models like FSSVM-HR by demonstrating the mathematical interpretations of each feature selection methodology applied to the attributes of the horse racing dataset.
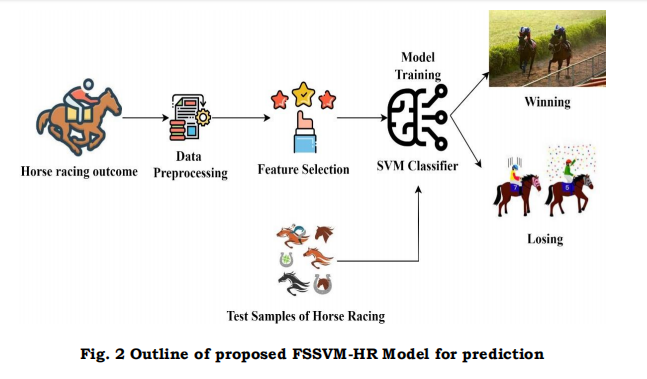
To determine how well the model works, we utilize metrics like recall, precision, dependability, F1 score, and ROC region. The final models need to be tested using the test data sets as a part of the model's verification and evaluation procedure to determine the breadth and durability. Validation cross-validation ensures dependable service across different data sets. Finally, compare and contrast the effectiveness of different artificial intelligence algorithms and examine the impact of feature selection on any model to assess and understand results. Give a brief synopsis of the study's key findings and an evaluation of the different artificial intelligence methods. Outline the limitations that were discovered and propose areas that require future investigation, such as exploring contemporary modeling techniques or exploring other information sets. Fig. 2 illustrates the outline of the proposed FSSVM-HR model for prediction.
Model Training:
A training set and a testing set are created from the dataset. The FSSVM-HR model is trained using the training set, and its performance is evaluated using the testing set. Using the training dataset, the support vector machine model is trained. During training, the algorithm seeks the hyperplane that best divides horses into winning and non-winning groups with the least amount of error and the largest margin. The model suggests that the task at hand is to estimate the outcomes of horse races using ML techniques in conjunction with careful feature selection. Each horse racing instance 𝑖 is represented as a feature vector 𝑥𝑖with 𝑛 features is represented using an Eq. (2). 𝑥𝑖 = (𝑥𝑖1, 𝑥𝑖2, … , 𝑥𝑖𝑛) (2)
For classification and regression applications, the support vector machine (SVM) is a well-liked controlled learning method. Predicting jockeying outcomes using support vector machines allows one to classify a horse race's outcome (such as victory, location, or display) based on factors including the horse's performance history, the trainer's reputation, the conditions at the venue, and more. Using the SVM method, the formula for a task assignment usually looks as given in Eq. (3). 𝑓(𝑥) = 𝑠𝑔𝑛(𝑤. 𝑥 + 𝑏) (3)
The choice factor 𝑓(𝑥), which provides the projected category name. When making a decision, the weight of each attribute is represented by the vector's value, 𝑤. Racetrack conditions, rider information, and horse behavior evaluations are all part of the characteristic vector (𝑥). The bias term 𝑏 helps to shift the choice limit. Depending on whether the value entered is positive or negative, the signification operation, 𝑠𝑔𝑛(), returns either -1 or 1, depending on the category. A labeled collection of prior jockey data, including results and related features, is fed into the SVM model. In order to minimize classification errors and maximize the distance between categories, the SVM model seeks out the optimal values 𝑤 and bias 𝑏. For optimal training to predict horse racing outcome Eq. (4) follows the mathematical computation like given below: 𝑚𝑖𝑛𝑤,𝑏 1/2‖𝑤‖2 + 𝑐 ∑𝑚 𝜉𝑖 𝑖=1 (4)
subject to 𝑦𝑖 (𝑤𝑇𝑥𝑖 + 𝑏) ≥ 1 − 𝜉𝑖 where 𝜉𝑖 ≥ 0 The variable 𝑦𝑖 defines the actual outcome of a class of horse race winning or losing with a decision boundary based on different classes based on features. The term 𝜉𝑖 defines the distance of a data point from the correct side of the decision boundary for horse racing prediction as margin of error. The regularization term is defined as 𝑐 that allows more flexibility of the model for avoiding overfitting. A critical step in this process is selecting attributes. Finding the most relevant attributes for the forecasting job and removing irrelevant or unnecessary data is what this processis all about. Model accuracy and reduction of unnecessary fitting can be achieved by careful variable selection. A support vector machine (SVM) algorithm can be trained with new data to predict how horses will do in forthcoming races.
Algorithm: FSSVM-HR Model
Input: Horse Racing Dataset
Output: Racing Outcome Prediction (Winning / losing)
Step 1: # Load and preprocess dataset
𝑥 = load_dataset("horse_racing.csv")
𝑥 = preprocess_data (𝑥𝑖 = (𝑥𝑖1, 𝑥𝑖2, … , 𝑥𝑖𝑛))
Step 2: # Split dataset into train, val, test
X_train, X_val, X_test, y_train, y_val, y_test = split_dataset
Step 3: # Feature Selection
potential_features = identify_relevant_features(𝑥_train)
selected_features = apply_𝑅𝐹𝐸𝑆𝑉𝑀 (𝑥_train, 𝑦_train)
Evaluate 𝑅𝐹𝐸𝑆𝑉𝑀 = 𝑎𝑟𝑔𝑚𝑖𝑛𝑥
′𝐶𝑉(𝑥
′)
for 𝑥, 𝑦 in data do
if 𝑦 ∗ (𝑤. 𝑇 ∗ 𝑥 + 𝑏) >= 1 then
continue
else
𝑤 = 𝑤 + 𝑦 ∗ 𝑥
𝑏 = 𝑏 + 𝑦
end for
Step 4: # Train FSSVM-HR model
train_svm(svm_model, 𝑥_train[𝑓(𝑥) = 𝑠𝑔𝑛(𝑤. 𝑥 + 𝑏)], 𝑦_train)
Compute 𝑚𝑖𝑛𝑤,𝑏
1
2
‖𝑤‖
2 + 𝑐 ∑𝑚 𝜉𝑖 𝑖=1
svm_acc = cal_accuracy(svm_preds, 𝑦_val) if 𝜉𝑖 ≥ 0
Step 5: # Perform model evaluation and prediction
models = [svm_model, cnn_model, rf_model, ann_model]
best_model = max ([𝑚.accuracy for 𝑚 in models])
specificity = calculate_precision(test_preds, 𝑦_test)
The steps to construct and test a model to predict the results of horse races are detailed in this pseudocode. Dataset loading and preprocessing is an integral part of this procedure, as is dividing the dataset into training, and test sets. The FSSVM-HR model is trained utilizing the features that were obtained through the feature selection process, which involves the use of RFE with SVM. After then, the model is tested for specificity and accuracy, and the one that performs the best is chosen to forecast the results of horse races.
Model Evaluation and Prediction:
In order to test the trained SVM model, and evaluate the testing dataset. To evaluate the model's predictive power, performance measures are computed, including prediction accuracy. The FSSVM-HR model can be used to forecast the results of future horse races once it has been trained and assessed. The proposed model can be trained to predict whether a horse will win or not based on its characteristics. The prediction phase involves determines the sign of the decision function.
4. Dataset Description
The information regarding horse racing betting across multiple countries and tracks in the Kaggle collections Horse Racing (kaggle.com) [27]. Because it contains detailed information on a wide variety of events and horses, the record set is a valuable resource for statistical research and learning algorithms. Important variables in the data set include the day and hour for each nationality, the running time in meters, the racetrack's kind and location, and the surface characteristics (Firm, Positive, Smooth, or Heavy), all of which affect the horses' output. Along with the jockey's age, identity, and identification, the data collection also includes the rider's and instructor's names, titles, and ages. Also included are wagering probabilities for each animal, which reveal information about their expected aptitude, and an inverted column that displays the outcome of the race for the jockey's horse. This massive data set allows for in-depth analysis of race conditions, jockey and horse performance, and race choices, among other statistical and forecasting issues plaguing the horse racing industry. The important variable includes res_win indicates that horse won or not and res_place defines that horse placed in a track or not. Table 1 defines the data attributes and description of the horse racing dataset.
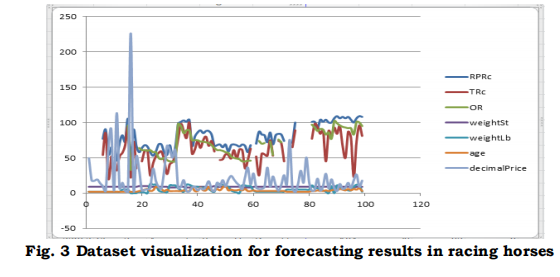
Fig 2 is a comprehensive checklist of all the horse races that have ever taken place, including a wide range of countries and routes. There are specifics regarding the location, time, and length of the race, in addition to the conditions of the track and the course itself, in it. Data such as division and name are included in the analysis for each competition, indicating the level of effort or quality. The competitive animals' names, ages, and loads (in kg and tonne units) are all part of the data set. The identities of the horses' handlers and riders are also revealed, providing an insight into the key figures in each race. Horses' shapes and speeds can be better understood with the use of efficiency measures like OR, RPR, TR. Furthermore, numerical betting odds are provided to convey a notion of the contest's likely outcomes. Taken together, the details paint a vivid picture of the races and the riders that took part in Fig. 3.
5. Experimental Analysis and Results
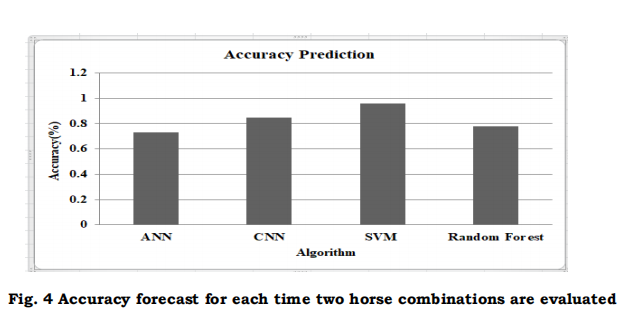
A comparative analysis of various methods employing machine learning for the purpose of horse racing forecasting is presented in Fig. 3. Among the other predictors, an SVM stood out with an astounding 96% accuracy. Reason being, SVM is very good with big datasets and does a great job of handling difficult classification problems. Following SVM, a CNN achieved an impressive 85% precision, proving its adaptability to process ordered data beyond images. Meanwhile, with a 73% accuracy rate, the Random Forest algorithm outperformed an ANN, which produced 78% reliable predictions. The other designs were more accurate, but ANN might still work in a combination to improve the performance of other algorithms. The best-performing architectures, SVM and CNN, provide trustworthy resources for those enthusiastic about using machine learning for racing predictions. Finally, the data demonstrates that all models are capable of making some predictions about the outcomes of horse riding. Fig. 4 illustrates the accuracy prediction of horse racing outcome compared to various algorithms. This can be obtained by the Eq. 5. 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑐𝑜𝑟𝑟𝑒𝑐𝑡 𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑖𝑜𝑛𝑠 𝑇𝑜𝑡𝑎𝑙 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑖𝑜𝑛𝑠 (5)
When it comes to estimating the outcomes of jockey races, the statistical models clearly differ in Fig.4. This is especially true when it comes to their ability to accurately identify horses that did not win. Among the four concepts, SVM stands out with an impressive 95% accuracy rate, showcasing its exceptional capability to accurately identify negative results. Random Forest, which offers a decent balance between accuracy and efficiency, comes in second with a strong specificity of 83%. Despite its middling effectiveness, CNN is a trustworthy alternative to ANN, demonstrating a 78% precision. An ANN's 62% accuracy is lower than the other designs, indicating that it can't detect animals that didn't win. Even though many models display varying degrees of accuracy, SVM is a valuable asset for jockey predictions because it reliably predicts non-winning outcomes. Although methods like CNN and random forest are also valuable additions to collaborative approaches to increase predicting accomplishment, ANN has the potential to remain beneficial in these contexts. Fig. 5 displays the specificity of horse racing outcome. This can be obtained by the Eq. 6. 𝑆𝑝𝑒𝑐𝑖𝑓𝑖𝑐𝑖𝑡𝑦 = 𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑙𝑦 𝑖𝑑𝑒𝑛𝑡𝑖𝑓𝑖𝑒𝑑 𝑛𝑜𝑛−𝑤𝑖𝑛𝑛𝑖𝑛𝑔 ℎ𝑜𝑟𝑠𝑒𝑠 𝑇𝑜𝑡𝑎𝑙 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑎𝑐𝑡𝑢𝑎𝑙 𝑛𝑜𝑛−𝑤𝑖𝑛𝑛𝑖𝑛𝑔 ℎ𝑜𝑟𝑠𝑒𝑠 (6)

6. Conclusion
The proposed research has achieved significant strides in the field of horse betting predictions, algorithm implementation for machine learning, and feature selection. Researchers have tested many methods, include SVM, CNN, ANN, & random forests, to see which ones are the most effective and dependable at accurately predicting the results of events. A number of machine learning algorithms were proposed, and their performance was compared according to sensitivity, precision, and other key metrics. In terms of sensitivity and precision, the study's primary conclusions reveal that SVM routinely outperforms competing methods. This exemplifies the algorithm's capability to process complicated data and differentiate between winning and losing cyclists. Both Random Forest and CNN have shown impressive results, making them viable alternatives to SVM and suggesting future opportunities for advancement. Unfortunately, ANN's reliability and precision were drastically lowered, suggesting that it might not be the best choice here as a standalone solution. The study may have only included data or characteristics directly connected to animal racing, which is a potential limitation. These factors may impact the equations' ability to be applied to other ethnic or environmental settings. Additionally, it is likely that not all of the featured design possibilities were examined during the assessment, which could have resulted in further improvements to the model's efficiency. In order to enhance model performance, future research efforts can look at more attributes and incorporate domain-specific data. This may depend on factors such as the horse's genetic makeup, the condition of course, or the abilities both rider and teacher. In order to better understand the elements that influence the outcomes of horse racing events, it is necessary to resolve concerns and focus on building larger models. This will ultimately lead to superior projections.
References :
[1]. Bishop, Cath. The Long Win-: There's more to success than you think. Practical Inspiration Publishing, 2024.
[2]. Ingrassia, Brian M. Speed Capital: Indianapolis Auto Racing and the Making of Modern America. University of Illinois Press, 2024.
[3]. Jaramillo, Manuel, Wilson Pavón, and Lisbeth Jaramillo. "Adaptive Forecasting in Energy Consumption: A Bibliometric Analysis and Review." Data 9.1 (2024): 13.
[4]. Miton, Helena. "A Tactful Tradition: The Role of Flexibility and Rigidity in Horse Riding and Dressage." (2024).
[5]. Forbes, Bronte, et al. "Associations between Racing Thoroughbred Movement Asymmetries and Racing and Training Direction." Animals 14.7 (2024): 1086.
[6]. Tondapu, Narayan. "Efficient Market Dynamics: Unraveling Informational Efficiency in UK Horse Racing Betting Markets Through Betfair's Time Series Analysis." arXiv preprint arXiv:2402.02623 (2024).
[7]. Oda, Daiki, and Akio Onogi. "Assessing the predictability of racing performance of Thoroughbreds using mixed‐effects model." Journal of Animal Breeding and Genetics 141.1 (2024): 24-32.
[8]. Berkani, Ahmed-Sami, et al. "Blockchain Use Cases in the Sports Industry: A Systematic Review." International Journal of Networked and Distributed Computing (2024): 1-24
[9]. Bandyopadhyay, Indranil. "Implementation Of An Artificial Intelligence And Machine Learning Powered Financial Decision-Support System For Stock Market Speculators." Educational Administration: Theory and Practice 30.4 (2024): 203-209.
[10]. Chen, Mike, ImanHonarvar, and HaraldLohre. "The current state of AI for investment management."
[11]. Obi, OguguaChimezie, et al. "Data science in sports analytics: A review of performance optimization and fan engagement." (2024).
[12]. Srinivasu, Parvathaneni Naga, et al. "An Interpretable Approach with Explainable AI for Heart Stroke Prediction." Diagnostics 14.2 (2024): 128.
[13]. Danışan, Sibel, BüşraYaranoğlu, and HülyaÖzen. "The relationship of personality traits with breed, sex, and racing performance in sport horses." Journal of Veterinary Behavior 71 (2024): 18-26.
[14]. Rokhsati, Hamidreza, et al. "An efficient computer-aided diagnosis model for classifying melanoma cancer using fuzzy-ID3-pvalue decision tree algorithm." Multimedia Tools and Applications (2024): 1-21.
[15]. deHaan, Evert, et al. "Unstructured data research in business: Toward a structured approach." Journal of Business Research 177 (2024): 114655.
[16]. Berkani, Ahmed-Sami, et al. "Blockchain Use Cases in the Sports Industry: A Systematic Review." International Journal of Networked and Distributed Computing (2024): 1-24.
[17]. WesterskovDalgas, Birgitte, KarstenElmose-Østerlund, and Thomas ViskumGjelstrupBredahl. "Exploring basic psychological needs within and across domains of physical activity." International Journal of Qualitative Studies on Health and Well-being 19.1 (2024): 2308994.
[18]. Bordeanu, Octavian Ciprian. From Data to Insights: Unraveling Spatio-Temporal Patterns of Cybercrime using NLP and Deep Learning. Diss. UCL (University College London), 2024.
[19]. Roy, Kaushik, ed. Artificial Intelligence, Ethics and the Future of Warfare: Global Perspectives. Taylor & Francis, 2024.
[20]. Gupta, Meenakshi, and Latika Singh. "Horse Race Results Prediction Using Machine Learning Algorithms With Feature Selection." International Journal of Intelligent Systems and Applications in Engineering 12.2s (2024): 132-139.
[21]. Zeng, Qingxuan. "Design and Implementation of Horse Riding Action Monitoring Platform Based on Deep Learning." 2023 IEEE International Conference on Control, Electronics and Computer Technology (ICCECT). IEEE, 2023.
[22]. CİHAN, Pınar. "Horse Surgery and Survival Prediction with Artificial Intelligence Models: Performance Comparison of Original, Imputed, Balanced, and Feature-Selected Datasets." KAFKAS ÜNİVERSİTESİ VETERİNER FAKÜLTESİ DERGİSİ 30.2 (2024).