HANDWRITING IDENTIFICATION AND VERIFICATION USING DEEP REINFORCEMENT LEARNING WITH CAPUCHIN OPTIMIZATION ALGORITHMS
Authors :
Mohd Hafeez and Chong Wei Ling
Address :
Department of Cloud Computing, Universiti Teknologi MARA, Malaysia
Department of Data Science, Universiti Sains Malaysia, Malaysiae
Abstract :
Handwriting is a way for people to express themselves through the written word. Character design is an art form in which everyone has their distinct flair. Biometrics and security applications rely on handwriting identification and verification. Inconsistencies in stroke velocity, pressure, and handwriting style diversity are common challenges for traditional approaches. Differences in pressure, stroke irregularities, and handwriting style provide problems for conventional approaches. This project proposed a novel method called DRLCOA-HI to improve handwriting identification and verification methods, both online and offline, by merging Deep Reinforcement Learning (DRL) with Capuchin Optimization Algorithms (COA). This approach uses DRL to determine the best ways to make decisions and extract features. Then, it uses Capuchin optimization to get the model's parameters and hyperparameters just right. The architecture is built around a dual-stream convolutional neural network that can extract features from offline and online stroke data. Then, a DRL agent determines the most important discriminative aspects. The DRL agent's policy and value functions are optimized using Capuchin optimization. Compared to current approaches, the results demonstrate substantial improvements in the accuracy of identification and verification. On average, the accuracy of offline identification increases by 8This technology is incredibly versatile and can be used for forensic and security purposes. It shows improved resilience against many sorts of forgeries and variations in digital and physical formats by 2%, and online verification accuracy increases by 7.1% and 6.8%. This technology is incredibly versatile and can be used for forensic and security purposes. It shows improved resilience against many forgeries and variations in digital and physical formats.
Keywords :
Handwriting identification, Deep Reinforcement Learning, Capuchin Optimization Algorithms.
1.Introduction
Biometrics is the study of unique human traits for secure identification and authentication. Biometric data, including fingerprints, DNA, handwriting, and signatures, cannot be identically held by two people [1]. Being able to write one's name, address, and other personal information legibly is a trait that sets most people apart from one another. Consequently, domain specialists can employ handwriting for forensic analysis, which could be useful for various purposes such as determining document authorship, detecting signature forgeries, verifying legal documents, etc. [2]. Handwritten signatures are legally recognized by financial and administrative entities around the world as a means of verifying an individual's identification. The fact that most users find adding a handwritten signature to be both non-invasive and non-threatening is an additional significant benefit [3]. Automated handwriting recognition might be considered a form of biometric identification. The process requires obtaining digital vector representation, having sufficient samples from various consumers of these vectors, and having a specific measurement or distance between them [4]. Securing and relying on electronic signature verification is crucial in this age of digital communication and the growing dependence on electronic transactions. Legal and financial documents have always relied on handwritten signatures to ensure their legitimacy and security [5].
This form of identification is problematic since it is easy for a forger to obtain someone else's handwriting and attempt to pass it off as their own. Moreover, since expert forgers try to mimic real signatures, the difference between real and fake signatures is subtle [6]. Online and offline methods of manuscript identification exist. In contrast to online approaches, which receive the coordinates in chronological order, representing the movements of the pen tip, offline methods merely have the image of the manuscript [7]. Since each script adds its distinct features that need to be properly identified and evaluated, the complexity increases when signatures are constructed in many scripts [8]. Over the last 20 years, there have been many attempts to use patterns in people's handwriting and fine motor abilities to verify their identities and determine their gender, age, handedness, and mental health [9]. Palaeographers still use time-consuming, labour-intensive, and expert-level procedures to identify the scribes who worked on medieval and modern manuscripts by looking for these distinguishing characteristics throughout the text [10]. Many optical character recognition (OCR) and handwriting apps and technologies are available today [11]. Discovering accurate and recognizable features among separate individual units, such as stroke or character classes, is a crucial step in developing an effective automated handwriting recognition system, regardless of the method used to recognize handwriting. Handwriting recognition's classification accuracy is impacted by this process, known as feature extraction [12].
There has been a growing need for strong methods to efficiently process offline and online handwriting, which has presented new problems to the discipline in recent years. Online handwriting analysis deals with real-time data that captures the spatial and temporal elements of writing on digital devices, unlike offline handwriting analysis, which focuses on static photographs of handwritten text. Online analysis must handle pressure and temporal stroke data, while offline analysis must deal with differences in writing devices and paper quality. It is still challenging to differentiate between real and fake handwriting, even though machine learning and computer vision have made great strides. Modern imitation tactics are very sophisticated, and there is a great deal of individual variation in writing styles. Additionally, assessing small aspects that may alter between offline and online samples is necessary, adding another layer of complexity.
The proposed method addresses these challenges by leveraging the power of DRL in combination with COA. DRL combines RL with DL, using a neural network to determine the policy or value function approximatively. In online handwriting, where temporal data like stroke order and pressure are crucial, DRL is used to learn a policy for distinguishing handwriting attributes. The COA optimises the learning rate, discount factor, exploration-exploitation balance, and other hyperparameters of the DRL model, drawing inspiration from the smart foraging behaviour of capuchin monkeys. To keep the DRL model from getting stuck in local optima, COA actively adjusts these parameters to increase its convergence rate. This optimization approach ensures the DRL model's adaptability to input scenarios and handwriting styles. The proposed system is capable of processing both online and offline handwritten data. The online scenario records real-time variables, including pressure, direction, and stroke speed, providing any identifying data. Without a network connection, the offline scenario entails obtaining scanned handwriting images' form, distance, and pixel distribution. The model is trained to generalise across both modalities to guarantee great accuracy in real-world applications that may face online and offline handwriting.
The significance of this study is that.
The following is the outline for the remainder of the paper. Section 2 describes various models and lists relevant recent research. Section 3 then presents the experimental data used to develop the suggested DRLCOA-HI model. Section 4 presents the research findings and compares the suggested methodology with existing ones. The paper is concluded in Section 5.
2. Literature Review
To address the problem of missing or incorrect signatures caused by illegible data, Majidpour J. et al. [13] proposed using the GAN model, a method for high-quality data synthesis. Additionally, a new method for signature verification is proposed, which makes use of a lightweight deep learning architecture. The suggested data synthesis mechanism is evaluated using three well-known CNN methods: MobileNet, SqueezeNet, and ShuffleNet. Training and testing the proposed model with several samples of such signatures demonstrates its ability to detect illegible and unrecognized ones.
In their initial investigation into Mongolian handwriting detection, Sun, Y. et al. [14] built a fundamentally simplistic convolutional neural network. The MWInet-12 system uses 12 convolution processes specifically developed to identify Mongolian handwriting. The MOLHW data set, which contains 156,372 samples provided by 125 writers, was utilized in the model assessment trials. The testing set ultimately produced impressive accuracy with a top-1 accuracy of 89.60% and a top-5 dependability of 97.53%.
Altwaijry and Al-Turaiki [15] suggested automatic handwriting detection using a CNN model. They introduced the Hijja dataset, which includes Arabic handwriting samples from children ranging in age from seven to twelve. While training this model, the Arabic Handwritten Character Dataset (AHCD) and Hijja were utilized. The model achieves impressive results on the AHCD dataset (97% accuracy) and the Hajj dataset (88% accuracy).
An approach based on guided Deep Convolutional Neural Networks (DCNNs) was suggested by Ahmed R. et al. [16]. The objective was to prevent overfitting while improving generalization performance compared to traditional deep learning implementations. Many deep layered convolutional layers went into the construction of the DCNN architecture. In experiments using TL for extracting features on the standard Arabic databases, the DCNN model beats modern Mobile Net and VGGNet-19 known and prepared models. The model carried out a generalizability demonstration with a precision of 99.68% and an excellent accuracy of 99.94% using the MNIST British isolated digits database.
The HandiText authentication technique, by Fang L. et al. [17], uses biometric and behavioural traits to verify an individual's identity securely. As an alternative to conventional authentication systems, it would alleviate problems like remembering complicated passwords and high false-negative and false-positive rates. The trial's findings proved that Long Short-Term Memory is the most effective in improving security while keeping user ease in mind, with a classification accuracy of 99%.
An ETEDL-THDR model based on deep learning was introduced by Vinotheni, C., and Pandian, S. L. [18]. The process begins with word-level segmentation and progresses to line-level segmentation. Two modules, line segmentation and line recognition, can be used to complete ETEDL-THDR text recognition. Additionally, feature vectors are derived using a MobileNet technique based on deep convolutional neural networks (DCNNs). To complete the process of Tamil character identification, a bidirectional gated recurrent unit (BiGRU) model and the water strider optimization (WSO) method are employed. Compared to more contemporary approaches, the text ETEDL-THDR model outperforms them with a 98.35% text F-measure, a sensitivity of 97.98%, an average precision of 98.38%, and a standard accuracy of 98.48%.
To improve Arabic Handwritten Recognition (AHR) performance, Alrobah, N., & Albahli, S. [19] proposed a comprehensive review of deep learning techniques, particularly CNNs. Issues addressed included the challenge of good recognition due to factors such as a tiny dataset and the cursive nature of Arabic writing. The outcomes proved that CNN-based models are more efficient and accurate compared to traditional methods.
Aqab and Tariq [20] proposed a method for digitizing handwritten text that employs ANN for character recognition in handwriting. As a result, the issue with previous optical character recognition (OCR) devices incorrectly distinguishing various handwriting styles was resolved. The results show that it significantly improves reliability and capability in character recognition, validating the efficacy of the ANN approach in processing and analyzing handwritten input.
3. Proposed Methodology
3.1 Dataset Explanation
Over 400 thousand handwritten names were gathered through charity organizations aiding poor children globally and are part of this study's dataset [21]. Optical character recognition (OCR) uses image processing technology to digitize the text on scanned documents. It usually works fine with machine-printed typefaces. Nevertheless, due to the vast differences in writing styles, it remains a formidable obstacle for computers to decipher handwritten characters. A total of 207,024 last names and 206,799 first names are included. There was a training set with 331,059 records, a testing set with 41,382 documents, and a validation set with 41,382 records.
3.2 Working flow of the proposed methodology
The model's capacity to differentiate between various handwriting samples is enhanced through the iterative use of DRL to learn handwriting features in offline and online data. To prevent the DRL model from becoming stuck in local optima and improve its generalizability to unknown handwriting data, COA is utilized to optimize critical hyperparameters, including learning percentage, exploration-exploitation trade-offs, and convergence speed. Figure 1 shows the overall working process for the proposed DRLCOA-HI method.
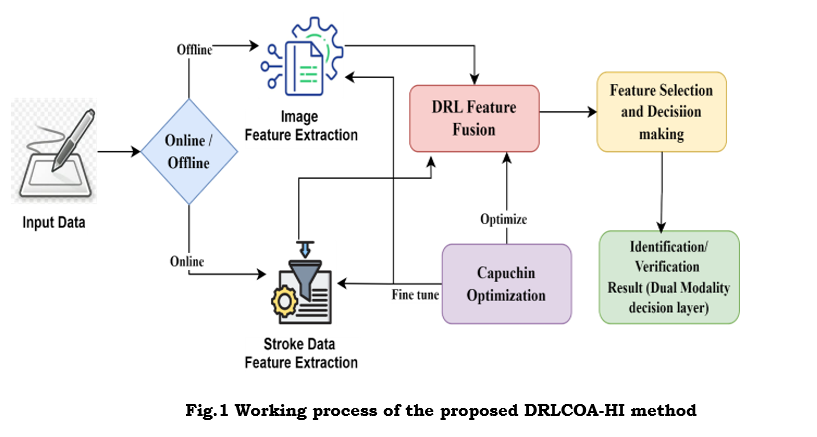
3.2.1 Data acquisition
Input image data are collected from the dataset mentioned above. Online handwritten data are collected from devices that capture real-time dynamic properties, including stroke direction, speed, and pressure. Input devices like digital pens, tablets, or styluses. Offline handwritten data are collected from character shape, spacing, and general structure extracted from scanned images or photos.
3.2.2 Data preprocessing (Feature Extraction)
In the DRLCOA-HI system, online and offline handwriting data undergo preprocessing to extract key features that can be used for handwriting identification and verification.
Online Data: Data collected in real-time from digital pens or tablets is known as online handwriting. These devices record dynamic parameters, including pressure, speed, and stroke direction along with the written strokes.
Stroke Sequence: The sequence of strokes is important for online handwriting. This can be represented as a series of points, as shown in Equation 1.

where x_k,y_k are the coordinates of the k th point in the stroke. The flow of handwriting can be better identified with this sequence.
Offline Data: Static handwritten text taken from pictures or scanned documents is called offline handwriting. In this scenario, the spatial arrangement of the handwriting is used to extract characteristics from pixel-based data.
Aspect Ratio: The handwriting style can be deduced from the height-to-width ratio of a letter or word. Equation 2 shows that the aspect ratio (A_r) is computed for every bounding box surrounding a character.

This is useful for recognizing handwriting styles that use compressed or stretched letters.
Feature Normalization: To ensure consistency, the above two features are standardized before the data is fed into the DRL model. This is done using min-max scaling as in the equation 3.

where a_i^' is the normalized feature, a_i is the extracted feature.
Feature Fusion: Both features are concatenated into a unified feature vector to combine the offline and online features. This allows the DRLCOA-HI system to handle both forms of handwriting inside its framework. Equation 4 displays the fused feature.

3.2.3 DRL Agent
The DRL module can extract features from offline and online handwriting data. It involves three steps: state, Action, and reward.
State: The current state of a DRL agent represents the features of the handwriting analysis sample. Attributes, including stroke designs, stress locations, and character development, can be extracted from handwriting to capture distinct features. Additionally, it contains the preprocessed picture data from the sample, which enables analysis down to the pixel level. Major data regarding the writing tool or writing surface and other relevant metadata concerning handwriting could be stored in the state. With this accurate state snapshot, the DRL agent can intelligently choose regarding handwriting validation or recognition.
Action: To detect handwriting, the DRL agent selects sample regions. An application includes focusing research efforts on an individual letter or a word. Some additional examples could include looking into tilt, baseline stability, or how letters relate. The agent can use a range of written characteristics or previous samples to assess the data. Attention to specifics permits quickly gathering the information necessary for identification or verification.
Reward: By adopting this structure in its handwriting analysis, the DRL agent presents suitable selections for identification or verification. Encouraging the agent to uphold its successful strategies through rewards for accurate identifications and verifications is achievable. The agent will be inspired to rethink its plan when facing failure and getting negative reinforcement. This small incentive system allows agents to develop their handwriting analysis skills and feel better about their capabilities.
3.2.4 Capuchin Optimization
The ability of capuchin monkeys to address problems has inspired a new technique in machine learning referred to as Capuchin Optimization. Capuchin Optimization implements an adaptive search technique to find novel food sources while simultaneously maximizing the benefits of existing resources, just as capuchin monkeys do while searching for food. The algorithm tends to use a group of agents to find the best answers. Capuchin Optimization agents can improve their performance in upcoming situations due to the ability to learn from past mistakes with data storage and retrieval.
3.2.5 Valuation and policy optimization for DRL agents
An agent from DRL can confirm and recognizing handwriting by examining and organizing handwritten samples. The DRL agent can better its capacity to correctly categorize handwriting samples and obtain essential information by transforming its decision-making protocol with the algorithm's parameters. By applying Capuchin Optimization, you can detect the persistent advantages of various activities within diverse settings by adjusting the importance function. The modification could increase the system's proficiency in telling apart real and fake handwriting samples.
3.2.5.1 Optimization of Feature Extraction Settings
Feature extraction represents an important function of this technique. The capability of the convolutional filter to recognize unique handwriting traits can be augmented via Capuchin Optimization. Capuchin Optimization permits the identification of the most effective combination of global and local features for precise identification.
This approach fine-tunes AI models concerning training rates, batch sizes, and network designs. With the support of Capuchin optimization, methods for normalizing, segmenting, and reducing distortion in handwritten data can be discovered. The use of ensemble learning in Capuchin Optimization could improve its overall performance by combining many models or features. This method can facilitate system adaptation to several languages and styles of handwriting by optimising the values for different features or classification criteria.
3.2.5.2 The cycle of Continuous Improvement
Improvements in the detection and verification of handwriting are heavily reliant on the Continuous Enhancement Cycle concept. The original model itself did not meet all quality expectations. Therefore, the first step is to begin iterative training on the improved version of the model. The target is to increase its effectiveness in learning and adapting. Capuchin Optimization is used at regular intervals to adjust both the architecture and the parameters of the model, usually after a certain number of training sessions or when performance improvements stop. Educating, refining, and maintaining the model on a continuous basis can improve its recognition and verification capabilities. Their ability to alter the DRL agent and feature extraction algorithms helps them adjust to novel challenges and handwriting styles.
3.2.5.3 Final Identification and Verification
After validation, the model faces extensive tests on benchmarks to learn about its flexibility. Achieving or exceeding the set performance criteria on this unknown data establishes that the model is usable in substantial applications. A detailed monitoring system tracks the model's performance during actual scenarios after its deployment. The system systematically follows the accuracy and efficiency of the model, initiating retraining or re-optimization processes when it detects a decline in performance or fresh patterns. The approach keeps the model timely and relevant by updating it to encompass developments in handwriting styles or unexpected difficulties in the business.
4. Results and discussion
4.1 Recognition ratio
Improving its dataset with either filled gaps or standardized data-gathering techniques is essential for the DRLCOA-HI system before it concludes its experimental evaluations. Once the model is trained, the third step is to test its preliminary effectiveness on a different validation set. According to the validation results, the model's parameters are changed. Evaluate the performance of the last, improved model using the held-out sample set regarding unseen data. Each of the three models—Deep Convolutional Neural Network [16], HandiText (LSTM) [17], and ETEDL-THDR [18]—receives training and evaluation from the same dataset. Thus, the comparisons are fair. Lastly, an array of metrics is used to compare the outcomes of the DRLCOA-HI model to those of these established methods. In jobs involving handwriting identification and verification, this aids in determining the merits and shortcomings of the suggested methodology.
4.2 Performance comparison
Here, standard approaches such as DCNN [16], LSTM [17], and the ETEDL-THDR model [18] are contrasted with the suggested DRLCOA-HI methodology using measures such as F1-Score, recall, accuracy, and precision. The model outperformed the current approaches, demonstrating superior performance on all measured outcomes. There was an improvement in the system's resistance to counterfeits and format modifications (digital and physical).
Precision: Of all the model's positive predictions, precision (P) indicates the percentage of accurate positive predictions. This is achieved by the equation 5.

where TP refers to the correctly identifying a genuine handwriting sample, FP refers to the misidentifying a forged handwriting sample as genuine
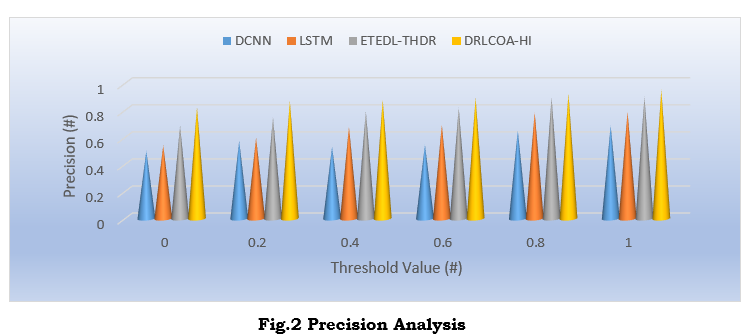
Figure 2 shows the precision analysis of the proposed method compared to the other proposed methods. Compared to other models, the DRLCOA-HI model performed better across all precision levels, as shown in the graph. Comparisons with other models, such as DCNN and LSTM, reveal that the DRLCOA-HI model achieves far higher levels of accuracy. This proves that the DRLCOA-HI model excels at reducing the number of false positives while recognizing handwriting, which makes it more trustworthy for practical use. The DRLCOA-HI model is a powerful tool for forensic analysis, biometrics, and court verification tasks due to its improved precision in dealing with online and offline handwritten alterations, forgeries, and noise.
Accuracy: Model accuracy in determining whether positive or negative handwriting samples are genuine or not. Evaluating the DRLCOA-HI system's capacity to differentiate between authentic and false handwriting relies heavily on the precision that is gained from equation 6. This system handles both online and offline handwriting data.

where TP that were properly recognized as authentic handwriting samples, TN the practice of accurately identifying samples of fake handwriting, FP refers to samples of fake handwriting that were mistakenly thought to be fake. and FN means real samples of handwriting that were mistakenly thought to be fake.
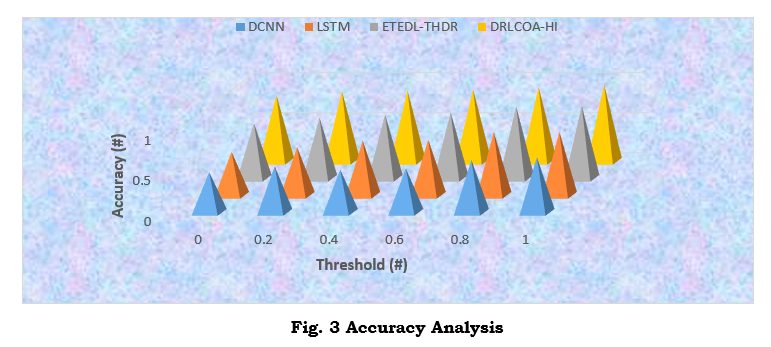
The accuracy analysis of the proposed method is displayed in Figure 3. The DRLCOA-HI model outperforms DCNN, LSTM, and ETEDL-THDR in accuracy. In every respect, the DRLCOA-HI model beats DCNN, LSTM, and ETEDL-THDR regarding accuracy rate. The suggested model is compatible with both digital and traditional handwriting. Because it can generalize and adapt to both forms of data, the DRLCOA-HI model is more versatile and accurate in real-world applications. Due to the DRLCOA-HI model's enhanced ability to distinguish between authentic and fake samples, the improved accuracy also suggests enhanced forgery detection. This is of the utmost importance for highly precise tasks like forensic document analysis and biometric authentication.
Recall: A vital performance indicator is recall, which quantifies the model’s accuracy in recognizing authentic handwriting samples. It quantifies the proportion of positive samples that are accurately classified as such. It could refer to the real positive rate or sensitivity. It can be obtained from the equation 7.

where TP the amount of authentic handwriting samples that were determined to be authentic and FN the number of real examples of handwriting that were mistakenly thought to be faked.
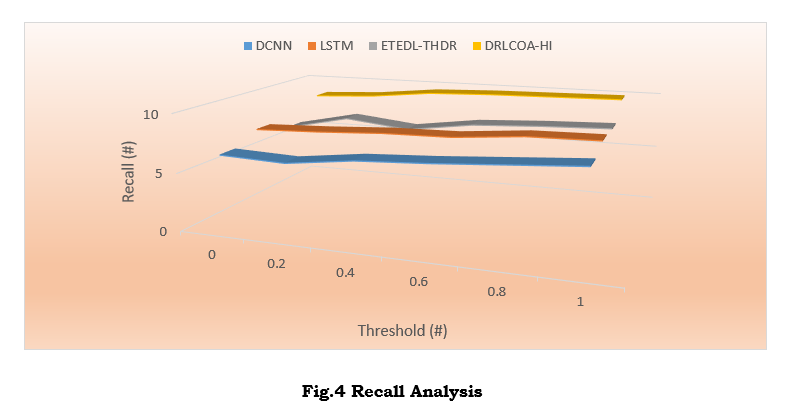
Figure 4 shows the Recall analysis. The DRLCOA-HI model routinely shows better recall values than other models, suggesting it is better at identifying real handwriting samples (true positives). Maintaining a high recall rate is essential to the model to avoid false negatives, which occur when real handwriting is incorrectly identified as fake. Forensic investigations, legal document verification, and other situations where it is critical to avoid missing genuine samples benefit from a model with a high recall rate since it demonstrates its sensitivity to legitimate handwriting samples. The practical application of DRLCOA-HI relies on its ability to blend sensitivity and precision. The increased recall of the DRLCOA-HI model demonstrates its flexibility in handling various handwriting styles, ethnic scripts, and environmental factors.
F1-Score: F1 calculates its harmonic average of accuracy and recall, which results in providing a decent evaluation of model performance in cases with an assortment of category distribution, important false positives (FP), and false negatives (FN). The accuracy assessment of the model for handwriting identification and verification is more thorough with the F1 score. The analysis thinks about the relative precision and recall value through Equation 8.

where P and R are calculated using the results of solving equations 5 and 7, respectively.
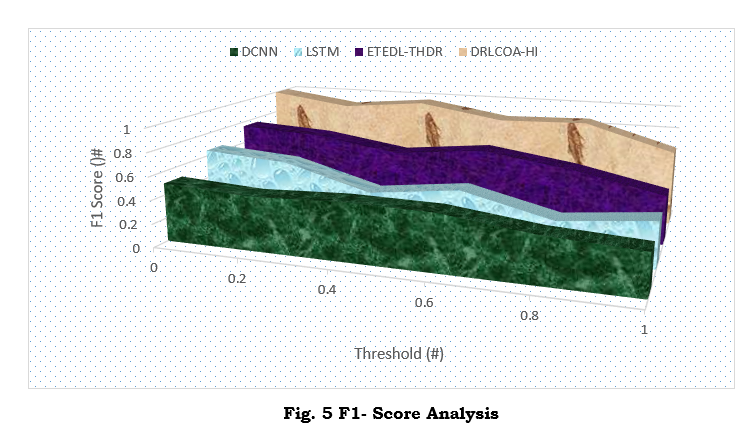
The F1-Score Analysis comparing the typical approaches with the new DRLCOA-HI approach shows the results presented in Figure 5. The F1-Score includes recall and precision to ensure a fuller understanding of how well the model is performing. Unlike DCNN, LSTM, and ETEDL-THDR, the DRLCOA-HI model accomplishes superior results related to F1-Score. The results indicate that DRLCOA-HI finds the optimal point of precision and recall concerning sample identification of authentic handwriting. As indicated by an improved F1-Score, the model created by the DRLCOA-HI can tell apart real from false handwriting samples. Although the model performs well in theory, especially when supplying comprehensive security solutions, the computational complexity renders it useless for real-time applications.
5. Conclusion
The DRLCOA-HI model unites DRL and COA to greatly improve handwriting validation and recognition. The models DCNN, LSTM, and ETEDL-THDR are surpassed by it in recall, accuracy, precision, and F1-Score. It can recognize writing by hand both on and off the internet. The model's resilience against forgeries and many environmental influences can improve through adapting to various handwriting styles. The improvements to hyperparameters made using COA and to feature extraction utilizing DRL have further strengthened its resilience. The model created by the DRLCOA-HI is helpful in forensics, biometric authorization, and legal verification because of its flexibility, ability to process multiple scripts and languages, and support for data analysis both online and offline. Better generalizability and stronger robustness mean it offers great capability for practical situations that need secure handwriting recognition.
References :
[1]. Tahir, N. M., Ausat, A. N., Bature, U. I., Abubakar, K. A., & Gambo, I. (2021). Off-line handwritten signature verification system: Artificial neural network approach. International Journal of Intelligent Systems and Applications, 10(1), 45.
[2]. Khan, M. A., Mohammad, N., Brahim, G. B., Bashar, A., & Latif, G. (2022). Writer verification of partially damaged handwritten Arabic documents based on individual character shapes. PeerJ Computer Science, 8, e955.
[3]. Jarrah, Muath, and Ahmed Abu-Khadrah. "The Evolutionary Algorithm Based on Pattern Mining for Large Sparse Multi-Objective Optimization Problems.", PatternIQ Mining.2024, (01)1, 12-22. https://doi.org/10.70023/piqm242
[4]. Foroozandeh, A., Hemmat, A. A., & Rabbani, H. (2020). Online handwritten signature verification and recognition based on dual-tree complex wavelet packet transform. Journal of Medical Signals & Sensors, 10(3), 145-157.
[5]. Saleem, S. I., & Abdulazeez, A. M. (2021). Hybrid Trainable System for Writer Identification of Arabic Handwriting. Computers, Materials & Continua, 68(3).
[6]. Abdirahma, A. A., Hashi, A. O., Elmi, M. A., & Rodriguez, O. E. R. (2024). Advancing Handwritten Signature Verification Through Deep Learning: A Comprehensive Study and High-Precision Approach. International Journal of Engineering Trends and Technology, 72(4), 81-91.
[7]. Xiao, W., & Ding, Y. (2022). A two-stage siamese network model for offline handwritten signature verification. symmetry, 14(6), 1216.
[8]. Ying, L. I. U., Meng, G., & ZHANG, N. (2024). Offline Author Identification using Non-Congruent Handwriting Data Based on Deep Convolutional Neural Network. International Journal of Advanced Computer Science & Applications, 15(3).
[9]. Singh, A., Saran, V., & Mahajan, M. Multiscript pattern recognition and handwritten signature verification system for forensic document examination.
[10]. Hasan, T., Rahim, M. A., Shin, J., Nishimura, S., & Hossain, M. N. (2024). Dynamics of digital pen-tablet: handwriting analysis for person identification using machine and deep learning techniques. IEEE Access.
[11]. Lastilla, L., Ammirati, S., Firmani, D., Komodakis, N., Merialdo, P., & Scardapane, S. (2022). Self-supervised learning for medieval handwriting identification: A case study from the Vatican Apostolic Library. Information Processing & Management, 59(3), 102875.
[12]. Chychkarov, Y., Serhiienko, A., Syrmamiikh, I., & Kargin, A. (2021). Handwritten Digits Recognition Using SVM, KNN, RF and Deep Learning Neural Networks. CMIS, 2864, 496-509.
[13]. Singh, S., Sharma, A., & Chauhan, V. K. (2021). Online handwritten Gurmukhi word recognition using fine-tuned deep convolutional neural network on offline features. Machine Learning with Applications, 5, 100037.
[14]. Majidpour, J., Oezyurt, F., Abdalla, M. H., Chu, Y. M., & Alotaibi, N. D. (2023). Unreadable offline handwriting signature verification based on generative adversarial network using lightweight deep learning architectures. Fractals, 31(6), 2340101.
[15]. Sun, Y., Fan, D., Wu, H., Wang, Z., & Tian, J. (2023). Offline Mongolian Handwriting Identification Based on Convolutional Neural Network. Electronics, 13(1), 111.
[16]. Altwaijry, N., & Al-Turaiki, I. (2021). Arabic handwriting recognition system using convolutional neural network. Neural Computing and Applications, 33(7), 2249-2261.
[17]. Ahmed, R., Gogate, M., Tahir, A., Dashtipour, K., Al-Tamimi, B., Hawalah, A., ... & Hussain, A. (2021). Novel deep convolutional neural network-based contextual recognition of Arabic handwritten scripts. Entropy, 23(3), 340.
[18]. Fang, L., Zhu, H., Lv, B., Liu, Z., Meng, W., Yu, Y., ... & Cao, Z. (2020). HandiText: Handwriting recognition based on dynamic characteristics with incremental LSTM. ACM Transactions on Data Science, 1(4), 1-18.
[19]. Vinotheni, C., & Pandian, S. L. (2023). End-to-end deep-learning-based tamil handwritten document recognition and classification model. IEEE Access, 11, 43195-43204.
[20]. Alrobah, N., & Albahli, S. (2022). Arabic handwritten recognition using deep learning: A survey. Arabian Journal for Science and Engineering, 47(8), 9943-9963.
[21]. Aqab, S., & Tariq, M. U. (2020). Handwriting recognition using artificial intelligence neural network and image processing. International Journal of Advanced Computer Science and Applications, 11(7).
[22]. https://www.kaggle.com/datasets/ssarkar445/handwriting-recognitionocr