DEVELOPING VISUAL QUESTIONS ANSWERING MODELS USING NATURAL LANGUAGE PROCESSING AND OPTIMIZED LEARNING MODEL
Authors :
Ali Fahim and Ahmed Rashid
Address :
Senior Researcher, Department of Information Systems, American University of Sharjah, UAE
Assistant Professor, Department of Computer Science, Khalifa University, UAE
Abstract :
As an aspect of AI, Visual Question Answering (VQA) integrates computer vision and natural language processing. It involves designing computer-based systems capable of automatically answering questions about images. Recently, VQA has received increasing attention owing to its potential to narrow the gap between image understanding and Natural Language Processing (NLP). However, the traditional models of VQA need better interpretations of meaning from complex visual data and hence formulate answers that are only sometimes contextually relevant; this seriously limits scalability and precision. This paper proposes a new approach called VQA-NLPFA, which seeks to overcome these limitations by developing an optimized VQA model that embeds NLP techniques into an advanced optimized learning model like the Firefly Algorithm. It can combine visual and textual information effectively, as the approach takes advantage of techniques related to multimodal data fusion. This model uses an attention mechanism using deep learning strategies that focus on the salient regions of the image, considering factors necessary for understanding the question. Hybrid algorithms optimize the learning model for better training speed and accuracy by reducing overfitting and enhancing feature selection. The preliminary experiments show that the proposed model of VQA-NLPFA outperforms traditional models with remarkably improved accuracies from difficult visual questions. The enhanced capability of understanding the context and generating accurate and more context-aware answers is accomplished. An optimized learning model further reduces the computational cost by a great amount, making the system much more scalable for real-world applications.
Keywords :
Visual questions and answers, Natural language processing, Firefly algorithm, Multimodal Data Fusion, Feature Selection, Image Understanding.
1.Introduction
It is an inherent task of any question-answering system and defines the ordered arrangement of inquiries. ‘A query can be answered if it can be stated at all’. In the previously stated basis, Wittgenstein established a connection between the act of questioning and the presence of a response [1]. Retrieving a natural language response to any given natural language question from a picture is the goal of visual questions and answering (VQA). Researchers have poured a lot of time and energy into this problem, and numerous cross-modal approaches have reached the cutting edge of performance [2]. To pass the Turing Test in spirit, the computer must demonstrate various human-like capabilities: visual recognition in the wild, language understanding, simple reasoning capability, and, importantly, background knowledge about the world. Since the problem of VQA was formulated, many of these aspects have been pursued [3]. A successful, robust, and unbiased VQA system is supposed to deduce the right answer from the right area of the image [4]. Figure 1 shows an example of the VQA.

The question-and-answer prompts can elicit multiple perspectives on the provided image and the intended topic and pertain to various instances in the image, such as items, sceneries, and actions. [5]. The most important factor when developing models for real-world applications is reliability, which can loosely be explained as the ability of the model to make as few mistakes as possible in cases where the model is uncertain [6]. To address these challenges, a model must first understand the topic, infer the relationships between pictures, and then utilize these relationships to establish relationships between items in different images [7]. Natural language processing (NLP) bridges the gap between computers and natural languages. This allows computers to have a grasp on and assess human language. [8]. This will likely also improve the relational representation between objects detected in an image or entities from a question and objects from an image by leveraging knowledge from outside, supportive facts. It also includes information about how the answer can be obtained from the question [9]. Attention mechanism-based approaches often combine question and picture representations according to the learnt significance of words and objects. Machine understanding of picture content and exterior previous data spanning common sense to comprehensive understanding is often required when VQA is implemented in real-life situations [10].
Most traditional VQA models suffer from these complex situations due to a lack of data fusion and interpretation of context. Visual and textual information alignment remains inappropriate, leading to mismatched responses and contextually irrelevant answers. The VQA-NLPIFA model, overcoming traditional models' deficiencies, integrates NLP techniques and optimization via the Firefly Algorithm. This improves the multimodal data fusion, leveraging NLP to extract deeper semantic meaning from questions and explain complex sentence structures while incorporating a deep learning-based attention mechanism that focuses on the salient regions of an image concerning a query. It also integrates the Firefly Algorithm to optimize performance, enhance feature selection, reduce overfitting, and increase training speed. This illustrates that VQA-NLPFA comes up with contextually relevant answers and, overall, can manipulate the visual data much better in offering superior performance on accuracy and training speed with enhanced generalization across different tasks of VQA.
The primary significance of this study is
The proposed approach VQA-NLPFA is an improved version of VQA, representing a conglomeration of advanced techniques of NLP, deep learning-based attention mechanism, and optimization by Firefly Algorithm. This model focuses on key regions of an image relevant to the question and improves interpretation and accuracy in answering complex visual queries. It can optimize learning VQA by reducing overfitting and improving training speed. Its performance is superior to that of traditional VQA models. Therefore, VQA-NLPFA enhances the accuracy of context-sensitive answering and computational costs to make it more scalable for practical use.
2. Related work
Li P. et al. [11] proposed that the work includes new ideas for improving VQA via GANs, autoencoders, and attention mechanisms. Such methods mitigated the problems of generating accurate answers from complex visual and linguistic inputs. The result suggested that while GANs perform well, the autoencoder techniques outperform them slightly with better learning of optimal embeddings. Attention mechanisms also enhanced the understanding of language priors, making them effective in solving complex tasks in VQA.
Li, L. et al. [12] proposed some in-context configuration strategies that enhance the performance of VQA with LVLMs. Similar-image-and-question-based demonstration retrieval and manipulating in-context sequences are introduced for better learning. The results are remarkable, especially when similar images and questions are used, entailing efficiency in the explored strategies and capability optimization of LVLMs to execute VQA.
Qian, T. et al. [13] introduced a benchmark, NuScenes-QA, composed of 34,000 scenes with 460,000 question-answer pairs for VQA in autonomous driving by integrating multi-modal data like camera images and LiDAR point clouds. It handled real-time, multi-frame, and multi-modal visual data complexities in autonomous driving that traditional VQA datasets cannot address. Techniques included scene graphs, manually designed question templates, and more. It represents a comprehensive benchmark with diverse question types, hence showing gaps in the performance of existing models and motivating research within autonomous driving VQA.
Chen P. et al. [14] proposed the Rank VQA model, which relies on a hybrid strategy inspired by ranking to improve its performance in VQA. Rank VQA used trained BERT (Bidirectional Encoder Representations from Transformers) model semantic textual features and high-quality visual characteristics from a Faster Region-based Convolutional Neural Network (R-CNN) model. The experimental results show that on the average level datasets VQA, RankVQA significantly beats all current models. It achieves 71.5% accuracy with a Mean Reciprocal Rank (MRR) of 0.75 for VQA v2.0, while for COCO-QA, the model achieves 72.3% accuracy with an MRR of 0.76.
Wu, K. [15] used a gated attention-based visual question-answering methodology. The model is designed to include an RNN for answer prediction and a visual inference network to extract complex problem features. It addressed the low accuracy in complex questions by strengthening the inference capabilities to leverage semantic information from text and images to build cross-modal associations. The suggested model considerably surpasses the present state-of-the-art, according to experimental findings on complicated questions running on the VQA dataset.
Mohamed, S. S. N., & Srinivasan, K. [16] proposed a VQA system for the medical domain that leverages the Visual Geometry Group Network (VGGNet) and Long Short-Term Memory (LSTM) techniques to extract features and fusion in medical images to answer related questions. It is designed so that image and text features will be well-processed and concatenated, improving response accuracy. Thus, the model can provide an accuracy score of 0.282 and a BLEU score of 0.330, showing great promise in enhancing medical image interpretation and decision-making.
Kolling C. et al. [17] presented a comprehensive analysis of VQA models, focusing on the impact of different components such as question representation, visual feature extraction, and attention mechanisms. More precisely, it tries to identify what elements are crucial in providing maximum predictive performance. From a methodological point of view, this involves exhaustive experiments with over 130 neural network models with different strategies. It found that simple architectures can achieve competitive performance, while state-of-the-art performance requires attention mechanisms and pre-trained embeddings.
Lan, Y. et al. [18] propose a method to boost Zero-shot VQA precision by generating Reasoning Question Prompts that disambiguate ambiguous questions. The technique aims to bridge the semantic space between picture descriptions and inquiries by making LLMs' understanding of queries possible and, hence, giving relevant answers. The experimental results have proved that the proposed method significantly enhances VQA's performance, ensuring cutting-edge findings across many datasets by providing much better guidance to LLMs while reasoning.
3. Proposed Methodology
3.1 Natural Language Processing (NLP)
Natural Language Processing, NLP, is a subfield of computer science and AI that aids computers through the application of machine learning to achieve human language understanding and interpretation capabilities. With NLP, the interaction between computers and other digital devices and texts and speeches is possible using combined with statistical modelling, deep learning, machine learning, computational linguistics, or rule-based modelling of human language.
Natural language processing (NLP) harnesses the potential of deep learning and machine learning techniques with computational linguistics. There are two main kinds of analysis in computational linguistics—syntactical and semantical—that use data science to examine language and speech. Syntactical analysis applies preprogrammed grammar rules to the syntax of words to establish their meanings in phrases, sentences, and other written forms. Word meanings are inferred from syntactic analysis output through sentence structure interpretation in semantic analysis.
Some of the linguistic tasks are
Coreference resolution is finding instances where two terms mean the same thing. One of the simplest cases is finding out who or what a particular pronoun refers to; for example, "she" = "Mary." In other cases, though, it may decipher idioms and metaphors within the text, such as when the "bear" is a big, hairy human being rather than an animal.
Named entity recognition (NER) finds useful words and phrases. NER identifies “London” and “Maria” as places and names, respectively.
Part-of-speech tagging is grammatical tagging, which determines the correct language component for a writing element according to its context and usage. Part of speech would classify "make" as both an adjective and a verb in the sentences "I can make a paper plane" and "What make of car do you own?"
Defining senses of words is the act of assigning a single meaning to a term that can have multiple meanings. A semantic analysis method is employed, which considers the word's context. For example, disambiguation of words differentiates between the meanings of the verb "make" in "make the grade" and "make a bet." Teasing out "I will be merry when I marry Mary" involves quite a high degree of complexity within the NLP system.
3.2 Overall workflow of the proposed methodology
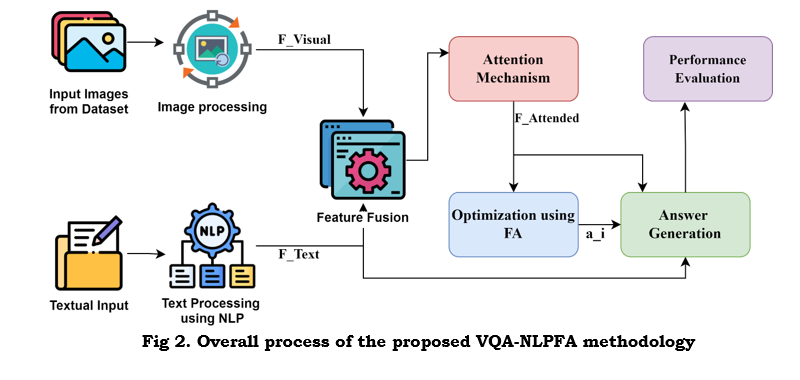
Figure 2 summarizes the process of the methodology VQA-NLPFA, which integrates image and text data to realize visual question answering. In this process, CNNs extract features from images while NLP methods, including BERT, are adopted to preprocess the questions. The features are then combined into a multi-modal representation, which equips the model with the capability to associate visual elements with the query. An attention mechanism highlights relevant regions of an image for more accurate answers. The Firefly Algorithm optimizes parameters such as learning rates and feature selection to enhance the speed and efficiency of training. Finally, the model decodes combined visual and textual information into an answer. The detailed explanation is as follows.
i) Input image processing
The input image 𝐼 is passed through a convolutional neural network to extract visual information. To dynamically learn and discern spatial hierarchies of characteristics from input images, convolutional neural networks (CNNs) are designed. For example, with RGB images, there are three color channels, and the input image 𝐼 can be expressed as a tensor with dimensions H × W × C. Here, H is the image's height, W is its width, and C is the color channel count. The first equation represents the CNN's output.

where F_visual is the output feature tensor. It captures local patterns such as edges, textures, and higher-level features crucial for understanding the image's content.
ii) Textual input processing
Question Q is processed using a language model like BERT. It is tokenized and embedded into a high-dimensional vector space.
Let equation 2 represent the question as a sequence of tokens,

where q_i are individual words. The embedding process converts this into a feature representation, F_text using a model NLP.

BERT stands for Bidirectional Encoder Representations from Transformers. It is a powerful deep model in natural language processing. This has revolutionised many NLP tasks by providing deep bidirectional text representations. It takes an input sequence of tokens where each token is represented as the sum of three embeddings: token embeddings-for what the word means, segment embeddings-which sentence does the word belong to, and position embeddings-what position in the sentence is this word at? With this much input detail, BERT manages to capture certain contextual subtlety. During pre-training, there are two major tasks that BERT engages in: the Masked Language Model, which decides whether two given sentences logically follow on from each other to help the model understand the relationship between sentences. After pre-training, BERT can be fine-tuned on any NLP task, such as question answering or sentiment analysis, letting it specialize in its general language understanding.
iii) Multimodel Feature Fusion
In the VQA system, information usually requires these two different modalities: visual features extracted based on visual and linguistic elements extracted from questions. This is called multimodal feature fusion. Once the linguistic and visual characteristics have been obtained, the next step is to fuse these features into a combined representation, as shown in Equation 4.
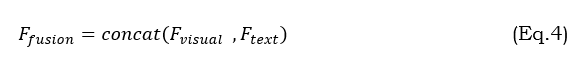
where F_fusion is the fused feature representation. F_visual ,F_text are obtained from equations 1 and 3.
iv) Attention Mechanism
Attention is crucial for any VQA system to focus on the areas of the image that are most relevant to the question. Concretely, it computes attention weights over regions in the image conditioned on both the visual features extracted from the image and the question embedding. These are subsequently used to compute the weighted sum of the visual features, obtaining an attended visual representation. Since the attention mechanism has the potential to enhance accuracy, interpretability, and efficiency, the attention mechanism forms an important ingredient of state-of-the-art VQA systems. This is particularly effective in questions focusing on parts of the image, for instance, "What colour is the car in the top left corner?" or "How many people are wearing hats?". This mechanism significantly enhances the model's capability for accurate answers by highlighting crucial visual information, improving interpretability because of more visualizable attention weights, and enabling the handling of complex questions that require focus on specific parts of an image.
Let the attention weight for the i-th region of the image be denoted as β_i which is computed as in equation 5.

where e_i is the attention score for the i th region, and N is the total number of image regions.
The attention score e_i can be computed as in equation 6 using the dot product between the visual features (F_visual) and the question of representation (F_text).

The attention weights are then used to compute a weighted sum of the visual features as in equation 7.

v) Optimization Using Firefly Algorithm (FA)
The VQA-NLPFA technique is nature-inspired optimization based on the Firefly Algorithm. This method aimed to optimize feature selection and tune hyperparameters in the model. In an algorithm of fireflies, they are considered the moving solutions in the optimisation space. In VQA-NLPFA, all main parameters of the model have been optimized by the Firefly Algorithm. In the case of a learning rate, each firefly will represent one value, where the brightness signifies the model's performance while guiding the movement to faster convergence. Fireflies also study various numbers of attention heads to achieve a good balance between model complexity and performance. In feature selection, fireflies represent the weights where the brightness is directly related to the model's ability to give importance to critical features. The FA also optimizes regularization terms for better generalization and reduction in overfitting. All these parameters- learning rates, attention heads, feature weights, and regularization- are thus adjusted by FA to make the VQA-NLPFA model achieve the best accuracy with much efficiency and scalability while handling visual question-answering tasks.
Fireflies are typically initialized at random within the search space. For a d-dimensional optimization problem, this initialization can be expressed as in equation 8.
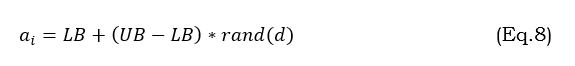
where a_i is the position of the ith firefly. UB,LB are the upper and lower bounds of the search space, and rand(d) generates a d-dimensional vector of random numbers between 0 and 1. The algorithm usually runs for a fixed number of iterations or until a satisfactory solution is found.
vi) Answer Generation
The final stage in any VQA system is generating the answer based on the obtained visual and textual information. It combines the attended visual features with textual features; a deep learning model decodes this multimodal representation into a textual answer. In the current VQA systems, attended visual features represent the most relevant parts of the image. They are first combined with the textual features extracted from the question into a multimodal representation. Then, this representation is passed through a decoder to generate the final answer. The final answer can be obtained by Equation 9.
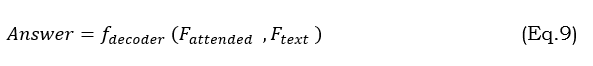
This decoder, f_decoder can be realized using many variants of deep learning architecture, including RNN. Equation 10 does exactly this.

where h_t is the secret state at each time interval t.
The model may generate answers during inference in the following ways:
Thus, the model's ability to deal with question types and give accurate contextual answers could be very different. It allows flexibility in choosing the type of decoder that may be used to adapt the VQA-NLPFA model for all sorts of different kinds of VQA tasks or datasets, thereby allowing further improvement of its performance across a wide range of question types and application domains.
4. Results and discussion
a. Dataset Explanation
The goal of visual quality assessment (VQA), a multimodal task, is to appropriately provide a natural language response as output given a picture and a question about the image. The process entails deciphering the image's meaning and connecting it to the query. Many sub-problems in CV and NLP (tasks like counting, item recognition, scene classification, etc.) are involved in VQA due to the requirement of contrasting the significance of data offered by the visual and the related verbal inquiry. As a result, it is deemed an AI-complete task.
b. Performance Metrics
This section compares traditional models such as GANs [11], Rank VQA [14], and Gated Attention with RNN [15] with the proposed VQA-NLPFA method. While conventional approaches leverage GANs, recurrent neural networks (RNNs), and attention mechanisms to generate answers from visual inputs, VQA-NLPFA enhances visual question answering by integrating multimodal data fusion, employing a deep learning-based attention mechanism and optimizing feature selection with the Firefly Algorithm. Performance metrics such as accuracy, training speed, Mean Reciprocal Rank, and computational cost comprehensively compare VQA-NLPFA with traditional models, evaluating model precision, efficiency, and scalability improvements.
i) Accuracy
Accuracy is a metric that evaluates the model VQA-NLPFA system's correctness in answering questions upon visual inputs. In terms of classification or prediction, it will provide the ratio of correct predictions or, in other words, answers done by the model concerning the total number of predictions. It can be calculated as in equation 11.

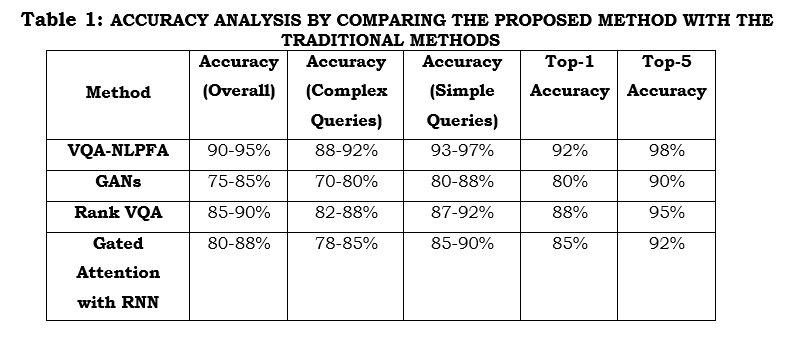
Table 1 provides an analysis of accuracy by comparing the proposed VQA-NLPFA model with traditional methods like GANs, Rank VQA, and Gated Attention with RNN across five key metrics: Overall Accuracy, Accuracy for Complex Queries, Accuracy for Simple Queries, Top-1 Accuracy, and Top-5 Accuracy. VQA-NLPFA reaching an overall accuracy of 95%. Since the complex queries involve the identification of attributes of objects in an image, the VQA-NLPFA scores 92%. This outperforms the best performance achieved by GANs, 70-80%, and Gated Attention with RNN at 85% since FA-enabled algorithms focus on the key regions in an image. In simple queries, this reaches up to 97%, outperforming GAN-based techniques which perform best at 80-88%, and Rank VQA at 92%. VQA-NLPFA reached a high Top-1 accuracy at 92%, and at an almost perfect score in Top-5 accuracy for different kinds of question types, its superior performance is nicely demonstrated at 98%.
ii) Training Speed
The rate at which a VQA model can absorb and apply new knowledge from training data is called its training speed. The common units of measurement are examples per second (e/s) or examples per hour (e/h), which represent the number of training examples processed per unit of time. Variables Influencing the Training Rate: Model intricacy, Resources available in hardware (GPU/TPU), Quantity of batches, Effectiveness of data preparation algorithm. Equation 12 shows the evaluation of training speed.
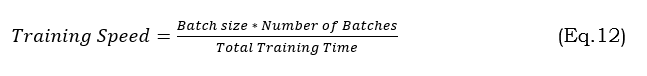
where Batch size refers to the quantity of samples handled in a forward or backward pass. Number of Batches refers to the total number of batches in an epoch, and Total Training Time is the time taken to complete one epoch (in seconds).
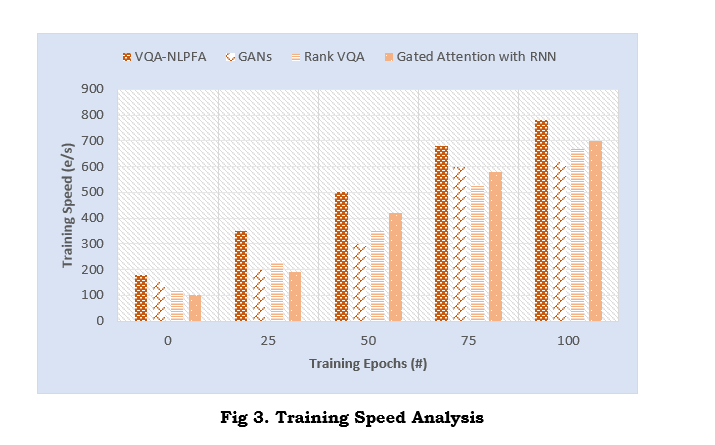
Figure 3 compares the training speed of the VQA-NLPFA model against those of other classic models, namely GANs, Rank VQA, and Gated Attention with RNN. From the figure, one observes that VQA-NLPFA reaches the highest training speed in several stages of training. Such performance is obviously due to the optimization by the Firefly Algorithm, hence speeding up the convergence through faster parameter tunings and feature selections and reducing overfitting. With improved training speed, the model is more efficient for practical purposes where time plays an important role compared to traditional models that require more computational resources and thus take longer in training.
iii) Mean Reciprocal Rank (MRR)
Mean Reciprocal Rank (MRR) is an evaluation metric for information retrieval and question-answering tasks. It considers the average inverse ranks of the right responses throughout a collection of questions or queries. In VQA, a model typically generates a ranked list of potential answers for each question-image pair. MRR helps evaluate how well the model ranks the correct answer among these candidates. It is obtained from the equation 13.

where |Q| is the sum of all inquiries rank_i is the rank of the first right response for the i th question.
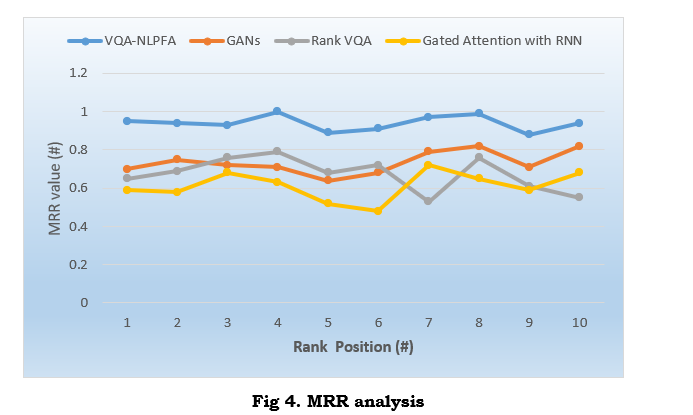
Figure 4 shows the MRR performance comparison for VQA-NLPFA against different models such as GANs, Rank VQA, and Gated Attention with RNN. VQA-NLPFA has obtained higher MRR scores, which proves the ability to rank the correct answer in a better position. This is due to its higher advancement in the attention mechanism and feature fusion of multimodal data for establishing better interlinking between visual and textual features. Further feature selection optimization by the Firefly Algorithm enhances the accuracy of ranking. Therefore, while VQA-NLPFA presents outstanding performance in the case of providing correct answers for complex visual questions, the traditional models show a lack of ability to handle that complexity, which shows up as lower scores in MRR.
iv) Computational Cost
Computational cost in VQA refers to the resources required to process and answer questions about images. This includes time complexity, space complexity, and hardware requirements. It can be calculated using equation 14.
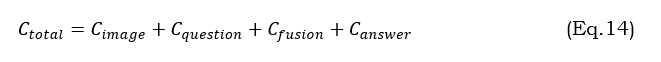
where C_image is the cost of image processing, C_question is the cost of question processing, C_fusion is the cost of multimodal fusion and C_answer is the cost of answer generation/classification.
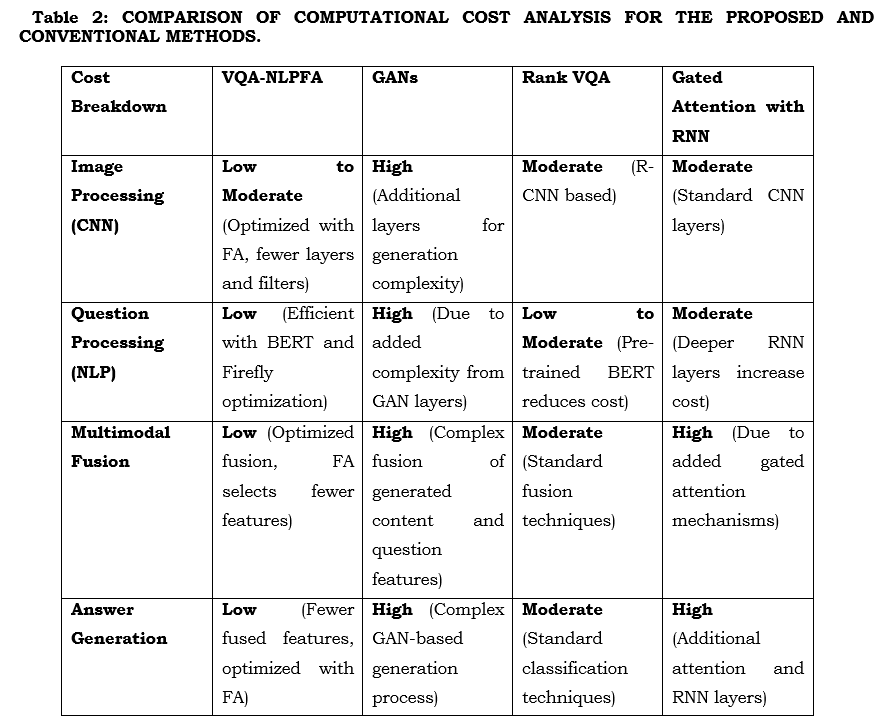
Table 2 compares the computational cost of VQA-NLPFA versus traditional models like GANs, Rank VQA, and Gated Attention with RNN. As a result of optimization by the Firefly Algorithm, VQA-NLPFA has lower computational costs at all steps: processing of the image, processing of questions, fusion of both, and finally producing the answer. This algorithm decreases complexity by choosing less but more representative features and fine-tuning the parameters, increasing efficiency. On the other hand, the GANs and RNN-based models incur a higher cost due to more additional layers and complex fusion processes that call for more resources. This all ensures better scalability for VQA-NLPFA in real-world applications by minimizing time and resource demands.
5. Conclusion
This work proposed the model VQA-NLPFA, incorporating NLP and FA for better performance in VQA tasks. That power ensues from the ability to fuse the multimodal data with optimized attention mechanisms that focus on salient regions of an image and interpret the elaborated query. The FA is essential in optimizing feature selection, enhancing speed, and reducing overfitting. This is indicative of the fact that VQA-NLPFA consistently outperforms the other traditional models like GANs, Rank VQA, and Gated-Attention with RNN, obviously reflected in their accuracy within various metrics such as overall accuracy, top-1 and top-5 accuracy, and finally Mean Reciprocal Rank. The robustness of this model concerning interpretation, even of simple and intricate visual and textual relationships, is efficient. Moreover, since most of the other models are far more computationally expensive than this one, it results in a scalable model for real-world applications. It can offer precision and efficiency in visual question-answering tasks. However, one limitation of the present model is that it relies heavily on computationally intensive attention mechanisms. Future work could also emphasise optimizing the attention mechanism to reduce this burden further, besides exploring the expansion of the model's ability to include more external knowledge in answering more varied open-ended questions.
References :
[1]. Gokhale, T., Banerjee, P., Baral, C., & Yang, Y. (2020, August). Vqa-lol: Visual question answering under the lens of logic. In European conference on computer vision (pp. 379-396). Cham: Springer International Publishing.
[2]. Gao, F., Ping, Q., Thattai, G., Reganti, A., Wu, Y. N., & Natarajan, P. (2022). Transform-retrieve-generate: Natural language-centric outside-knowledge visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5067-5077).
[3]. Schwenk, D., Khandelwal, A., Clark, C., Marino, K., & Mottaghi, R. (2022, October). A-okvqa: A benchmark for visual question answering using world knowledge. In European conference on computer vision (pp. 146-162). Cham: Springer Nature Switzerland.
[4]. Liang, Z., Jiang, W., Hu, H., & Zhu, J. (2020, November). Learning to contrast the counterfactual samples for robust visual question answering. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) (pp. 3285-3292).
[5]. Wang, H., & Ge, W. (2024). Q&A Prompts: Discovering Rich Visual Clues through Mining Question-Answer Prompts for VQA requiring Diverse World Knowledge. arXiv preprint arXiv:2401.10712.
[6]. Jarrah, Muath, and Ahmed Abu-Khadrah. "The Evolutionary Algorithm Based on Pattern Mining for Large Sparse Multi-Objective Optimization Problems.", PatternIQ Mining.2024, (01)1, 12-22. https://doi.org/10.70023/piqm242
[7]. Bansal, A., Zhang, Y., & Chellappa, R. (2020). Visual question answering on image sets. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16 (pp. 51-67). Springer International Publishing.
[8]. Torfi, A., Shirvani, R. A., Keneshloo, Y., Tavaf, N., & Fox, E. A. (2020). Natural language processing advancements by deep learning: A survey. arXiv preprint arXiv:2003.01200.
[9]. Gardères, F., Ziaeefard, M., Abeloos, B., & Lecue, F. (2020, November). Conceptbert: Concept-aware representation for visual question answering. In Findings of the Association for Computational Linguistics: EMNLP 2020 (pp. 489-498).
[10]. Pethuraj, M. S., bin Mohd Aboobaider, B., & Salahuddin, L. B. (2023). Analyzing QoS factor in 5 G communication using optimized data communication techniques for E-commerce applications. Optik, 272, 170333.
[11]. Li, P., Yang, Q., Geng, X., Zhou, W., Ding, Z., & Nian, Y. (2024). Exploring diverse methods in visual question answering. arXiv preprint arXiv:2404.13565.
[12]. Li, L., Peng, J., Chen, H., Gao, C., & Yang, X. (2024). How to configure good in-context sequence for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 26710-26720).
[13]. Qian, T., Chen, J., Zhuo, L., Jiao, Y., & Jiang, Y. G. (2024, March). Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 38, No. 5, pp. 4542-4550).
[14]. Chen, P., Zhang, Z., Dong, Y., Zhou, L., & Wang, H. (2024). Enhancing Visual Question Answering through Ranking-Based Hybrid Training and Multimodal Fusion. arXiv preprint arXiv:2408.07303.
[15]. Wu, K. (2024). Research and implementation of visual question and answer system based on deep learning. Applied Mathematics and Nonlinear Sciences, 9(1).
[16]. Mohamed, S. S. N., & Srinivasan, K. (2020, September). ImageCLEF 2020: An approach for Visual Question Answering using VGG-LSTM for Different Datasets. In CLEF (Working Notes).
[17]. Kolling, C., Wehrmann, J., & Barros, R. C. (2020, July). Component analysis for visual question answering architectures. In 2020 International Joint Conference on Neural Networks (IJCNN) (pp. 1-8). IEEE.
[18]. Lan, Y., Li, X., Liu, X., Li, Y., Qin, W., & Qian, W. (2023, October). Improving zero-shot visual question answering via large language models with reasoning question prompts. In Proceedings of the 31st ACM International Conference on Multimedia (pp. 4389-4400).
[19]. https://www.kaggle.com/datasets/bhavikardeshna/visual-question-answering-computer-vision-nlp